Go pprof 性能剖析优化实践
性能分析是软件工程师中被低估的技能,即使是非常有经验的开发人员也经常忽视它。对一个程序进行性能分析,实质上是测量CPU和内存的使用情况,以发现瓶颈、内存泄漏和其他性能问题。知道如何对程序进行性能分析并解释结果,可以帮助我们准确找到程序性能不佳的地方,并将优化工作集中在这些特定部分。在本文中,我们将对一个实际的Go程序进行性能分析。我们将学习如何解释结果、得出结论,并相应地优化程序。
Contents
本文分析的样例程序
地球上最热的地方在哪里?最冷的地方又在哪里?我们的程序与全球温度数据集进行交互,该数据集包含全球约85K个坐标点一百年的月平均气温。 我们的程序读取此数据集并输出一个包含所有坐标及其多年总平均气温的表格。
首先,让我们看看数据:
ls
...
air_temp.1901 air_temp.1912 air_temp.1923 air_temp.1934 air_temp.1945 air_temp.1956 air_temp.1967 air_temp.1978
air_temp.1902 air_temp.1913 air_temp.1924 air_temp.1935 air_temp.1946 air_temp.1957 air_temp.1968 air_temp.1979
...
每个文件包含该年每个坐标点的月平均气温。
每个文件的内容如下(展示一年的前三行):
head -n 3 air_temp.1990
-179.750 71.250 -24.7 -29.9 -24.4 -12.5 -2.6 0.4 2.2 4.2 -0.9 -5.9 -15.4 -25.5
-179.750 68.750 -29.9 -32.5 -22.5 -10.9 -3.7 0.7 2.8 3.6 -1.1 -8.7 -17.1 -27.5
-179.750 68.250 -31.0 -33.7 -23.6 -11.9 -4.5 0.9 3.3 3.6 -1.7 -9.7 -18.3 -28.2
前两列是坐标,后面的数据是月平均气温。
以下是我们的完整程序:
package main
import (
"encoding/csv"
"flag"
"fmt"
"io"
"os"
"strconv"
"strings"
)
type record struct {
lon, lat float64
temps [12]float64
}
func main() {
files, _ := os.ReadDir("data")
rawData := make(map[string][]byte)
for _, file := range files {
f, _ := os.Open("data/" + file.Name())
rawData[file.Name()], _ = io.ReadAll(f)
f.Close()
}
parsed := parseData(rawData)
output := make(map[string][]float64)
for _, v := range parsed {
for _, r := range v {
key := fmt.Sprintf("%.3f:%.3f", r.lat, r.lon)
output[key] = append(output[key], r.temps[:]...)
}
}
outputFile, _ := os.Create("output.csv")
w := csv.NewWriter(outputFile)
defer w.Flush()
defer outputFile.Close()
for coordinates, yearlyTemps := range output {
row := []string{coordinates, fmt.Sprintf("%.2f", average(yearlyTemps))}
w.Write(row)
}
}
func parseData(input map[string][]byte) map[string][]record {
m := make(map[string][]record)
for filename, v := range input {
lines := strings.Split(string(v), "\n")
for _, line := range lines {
seg := strings.Fields(line)
if len(seg) != 14 {
continue
}
lon, _ := strconv.ParseFloat(seg[0], 64)
lat, _ := strconv.ParseFloat(seg[1], 64)
temps := [12]float64{}
for i := 2; i < 14; i++ {
t, _ := strconv.ParseFloat(seg[i], 64)
temps[i-2] = t
}
m[filename] = append(m[filename], record{lon, lat, temps})
}
}
return m
}
func average(input []float64) float64 {
var sum float64
for _, v := range input {
sum += v
}
return sum / float64(len(input))
}
运行这个程序后,它会运行几秒钟,并生成一个名为output.csv的文件,包含结果。
以下是输出文件的前几行(从高到低排序):
column -t -s, output.csv | sort -k2 -nr | head -n 3
-9.750:-75.250 34.99
-10.250:-75.250 33.79
-10.250:-74.750 32.98
使用runtime/pprof进行性能分析
Go配备了一个非常棒的性能分析工具,叫做runtime/pprof。使用这个库,我们可以轻松地分析程序的CPU和内存使用情况。
CPU使用情况分析
CPU性能分析是基于时间的测量。我们希望知道每个函数执行需要多长时间。当我们使用runtime/pprof进行CPU性能分析时,我们的程序将在定期间隔(每秒100次)被短暂暂停以收集样本。我们收集的样本越多,结果就越准确。
由于我们的程序是一个具有定义结束点的单一短期过程,我们可以对整个程序进行分析。我们可以这样做:
import (
"flag"
"os"
"runtime/pprof"
//... other imports
)
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to this file")
func main() {
flag.Parse()
if *cpuprofile != "" {
cpuf, _ := os.Create(*cpuprofile)
pprof.StartCPUProfile(cpuf)
defer cpuf.Close()
defer pprof.StopCPUProfile()
}
// ...
}
当我们使用-cpuprofile标志运行程序时,它将开始CPU性能分析,并将结果写入指定文件。
内存使用情况分析
与CPU性能分析是通过一段时间内集成样本的收集不同,内存性能分析是在特定时刻的内存状态快照。如果可能,我们应该找到程序中的战略点进行快照。在我们的例子中,看起来如果我们将它放在写入输出文件的行之前可以获得很多信息。让我们也添加它:
// ...
var (
cpuprofile = flag.String("cpuprofile", "", "write cpu profile to this file")
memprofile = flag.String("memprofile", "", "write memory profile to this file")
)
func main() {
flag.Parse()
if *cpuprofile != "" {
cpuf, _ := os.Create(*cpuprofile)
pprof.StartCPUProfile(cpuf)
defer cpuf.Close()
defer pprof.StopCPUProfile()
}
// ... some code
if *memprofile != "" {
memf, _ := os.Create(*memprofile)
pprof.WriteHeapProfile(memf)
memf.Close()
}
for coordinates, yearlyTemps := range aggregated {
row := []string{coordinates, fmt.Sprintf("%.2f", average(yearlyTemps))}
w.Write(row)
}
}
分析 CPU profile
我们现在可以构建我们的程序并使用分析标志运行它:
go build -o bin main.go
./bin -cpuprofile=cpu.prof
./bin -memprofile=mem.prof
我之所以运行两次程序,是因为我想分别分析CPU和内存。如果我们同时使用两个标志运行程序,CPU分析结果将受到内存分析的影响,反之亦然。
到目前为止,我们应该有两个文件:cpu.prof和mem.prof。让我们分析结果。
运行go tool pprof
我们可以启动Go pprof工具并分析结果,先从CPU分析开始:
go tool pprof bin cpu.prof
File: bin
Type: cpu
Time: Apr 7, 2024 at 5:24pm (IDT)
Duration: 14.03s, Total samples = 14.05s (100.11%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
我们现在进入了pprof CLI,首先要做的事情是查看topN。
查看topN
让我们看看最耗CPU的前5个函数:
(pprof) top5
Showing nodes accounting for 7360ms, 52.38% of 14050ms total
Dropped 104 nodes (cum <= 70.25ms)
Showing top 5 nodes out of 72
flat flat% sum% cum cum%
2640ms 18.79% 18.79% 2640ms 18.79% runtime.memmove
1820ms 12.95% 31.74% 2560ms 18.22% strings.Fields
1600ms 11.39% 43.13% 1600ms 11.39% strconv.readFloat
800ms 5.69% 48.83% 800ms 5.69% strconv.(*decimal).Assign
500ms 3.56% 52.38% 500ms 3.56% strconv.atof64exact
- Flat - 该函数调用所花费的时间/百分比。
- Cum (累计) - 函数调用以及被其调用的函数所花费的时间/百分比(包括自身)。
看起来 runtime.memmove、strings.Fields 和 strconv.readFloat 花费了不少时间。
为了更好地理解,我们可以按累计排序前五名,看看谁在调用这些函数。
(pprof) top5 -cum
Showing nodes accounting for 0.47s, 3.35% of 14.05s total
Dropped 104 nodes (cum <= 0.07s)
Showing top 5 nodes out of 72
flat flat% sum% cum cum%
0.22s 1.57% 1.57% 13.81s 98.29% main.main
0 0% 1.57% 13.81s 98.29% runtime.main
0.11s 0.78% 2.35% 7.51s 53.45% main.parseData
0.02s 0.14% 2.49% 3.28s 23.35% fmt.Sprintf
0.12s 0.85% 3.35% 3.17s 22.56% strconv.ParseFloat
注意,runtime.main 占用了98.29%的累计时间,但 flat 时间为0%。这很合理,因为一切都由 runtime.main 调用,但函数本身并不占用CPU时间。我们还可以看到程序中调用的函数:main.parseData 是我们自己的函数,占用了整个过程的7.51秒。还有 fmt.Sprintf 和 strconv.ParseFloat 是我们在过程中调用的函数。
查看图表
虽然 topN 很好用,实际上大多数情况下它已经足够得出结论,但 pprof 工具还有一些更强大的诊断工具。为了更好地理解调用栈,我们可以查看交互图表。生成这个图表的方法有几种——我个人最喜欢的是启动一个捆绑所有 pprof 命令的服务器,在浏览器中显示漂亮的GUI。
你可能需要安装 graphviz。
go tool pprof -http localhost:6060 bin cpu.prof
我们可以使用页面顶部的搜索栏来缩小图表范围。
让我们搜索 main.parseData,看看为什么它耗时7.51秒。
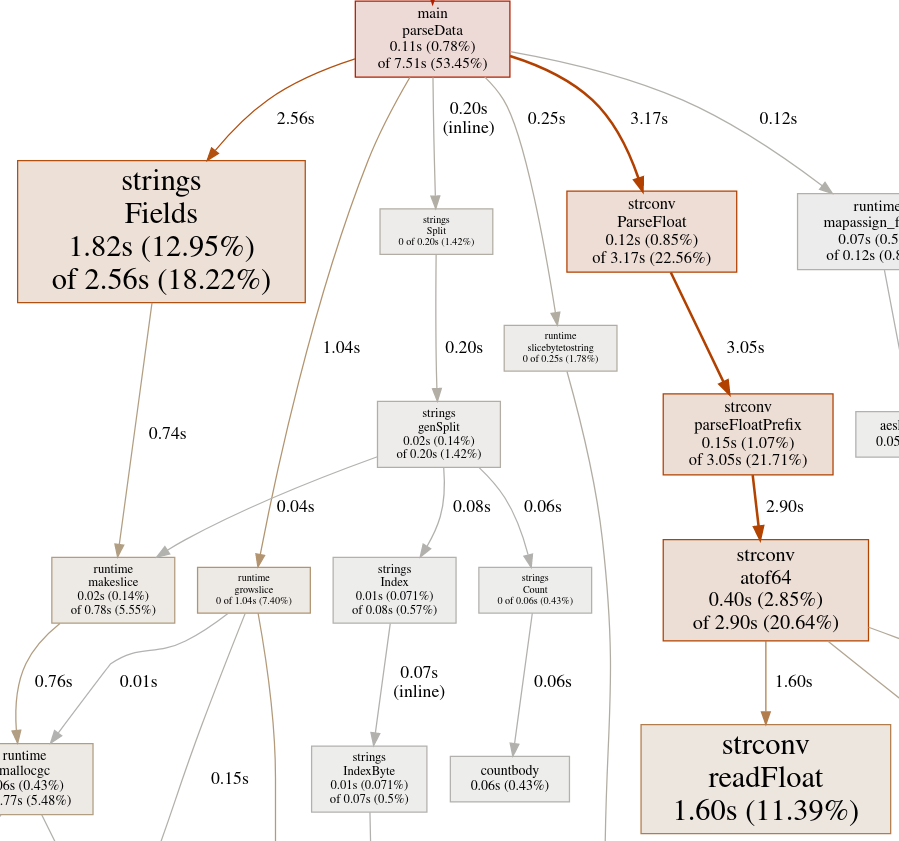
看起来 main.parseData 负责了大部分的CPU消耗。我们在优化代码时会记住这一点。
分析内存 profile
同样,topN 是你的首选命令,只不过在这种情况下,我们查看的是调用 pprof.WriteHeapProfile(memf) 时的内存快照。
go tool pprof bin mem.prof
File: bin
Type: inuse_space
Time: Apr 7, 2024 at 8:08pm (IDT)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top5
Showing nodes accounting for 1741.73MB, 99.91% of 1743.23MB total
Dropped 1 node (cum <= 8.72MB)
flat flat% sum% cum cum%
1194.12MB 68.50% 68.50% 1194.12MB 68.50% main.parseData
547.61MB 31.41% 99.91% 1743.23MB 100% main.main
0 0% 99.91% 1743.23MB 100% runtime.main
哇!main.parseData 占用了1.2G的内存!看起来 main.main 本身也占用了大约0.5G。因此,我们的CPU问题被更大的内存问题所掩盖。实际上,CPU问题可能与 main.parseData 的大内存有关,因为大量内存可能导致大量的内存移动(memmove)、内存分配(malloc)和垃圾回收(mallocgc)操作。
list(源代码分析)
pprof 工具提供了如此深入的分析,以至于我们甚至可以看到消耗最多内存的函数的源代码。让我们看看 main.parseData 的源代码:
(pprof) list parseData
Total: 1.70GB
ROUTINE ======================== main.parseData in /home/nyadgar/temp_analysis/main.go
1.17GB 1.17GB (flat, cum) 68.50% of Total
. . 68:func parseData(input map[string][]byte) map[string][]record {
. . 69: m := make(map[string][]record)
. . 70: for filename, v := range input {
. . 71: lines := strings.Split(string(v), "\n")
. . 72: for _, line := range lines {
. . 73: seg := strings.Fields(line)
. . 74: if len(seg) != 14 {
. . 75: continue
. . 76: }
. . 77: lon, _ := strconv.ParseFloat(seg[0], 64)
. . 78: lat, _ := strconv.ParseFloat(seg[1], 64)
. . 79: temps := [12]float64{}
. . 80: for i := 2; i < 14; i++ {
. . 81: t, _ := strconv.ParseFloat(seg[i], 64)
. . 82: temps[i-2] = t
. . 83: }
. . 84:
1.17GB 1.17GB 85: m[filename] = append(m[filename], record{lon, lat, temps})
. . 86: }
. . 87: }
. . 88:
. . 89: return m
. . 90:}
这并不令人惊讶。我们将整个数据集读入内存并解析成一个map,这是优化的好起点。
再看看 main.main 函数:
(pprof) list main.main
Total: 1.70GB
ROUTINE ======================== main.main in /home/nyadgar/temp_analysis/main.go
547.61MB 1.70GB (flat, cum) 100% of Total
. . 24:func main() {
. . 25: flag.Parse()
. . 26: if *cpuprofile != "" {
. . 27: cpuf, _ := os.Create(*cpuprofile)
. . 28: pprof.StartCPUProfile(cpuf)
. . 29: defer cpuf.Close()
. . 30: defer pprof.StopCPUProfile()
. . 31: }
. . 32:
. . 33: files, _ := os.ReadDir("data")
. . 34:
. . 35: rawData := make(map[string][]byte)
. . 36: for _, file := range files {
. . 37: f, _ := os.Open("data/" + file.Name())
. . 38: rawData[file.Name()], _ = io.ReadAll(f)
. . 39: f.Close()
. . 40: }
. . 41:
. 1.17GB 42: parsed := parseData(rawData)
. . 43: output := make(map[string][]float64)
. . 44: for _, v := range parsed {
. . 45: for _, r := range v {
. 1.50MB 46: key := fmt.Sprintf("%.3f:%.3f", r.lat, r.lon)
547.61MB 547.61MB 47: output[key] = append(output[key], r.temps[:]...)
我们这里有严重问题,先将整个数据集读入内存并解析成一个map,然后,我们创建了另一个新map,数据几乎相同,只是组织方式有点不同。
优化程序
在分析结果后,我们可以得出一些结论:
- 我们应该从优化 main.main 和 main.parseData 函数开始。与其将整个数据集读入内存,我们可以逐行读取并即时解析。这样可以节省大量内存和CPU时间。
- struct 可以更简单,只需将坐标作为一个字符串,并将温度作为一个float32平均值。
- 通过跳过程序中的一些不必要步骤,我们可以消除不必要的数据重复。
- 我们应该寻找更好的替代品来替换strconv.ParseFloat和(如果可能)strings.Fields函数。
- 在main.parseData中有两个strconv.ParseFloat调用我们可以移除。
- 我们可以避免使用fmt.Sprintf的地方,因为根据性能分析结果,这是一个相对昂贵的函数。
优化后的代码:
package main
import (
"bufio"
"encoding/csv"
"flag"
"fmt"
"os"
"runtime/pprof"
"strings"
"github.com/sugawarayuuta/refloat"
)
type record struct {
coords string
avg float32
}
var (
cpuprofile = flag.String("cpuprofile", "", "write cpu profile to this file")
memprofile = flag.String("memprofile", "", "write memory profile to this file")
)
func main() {
flag.Parse()
if *cpuprofile != "" {
cpuf, _ := os.Create(*cpuprofile)
pprof.StartCPUProfile(cpuf)
defer cpuf.Close()
defer pprof.StopCPUProfile()
}
files, _ := os.ReadDir("data")
aggregated := make(map[string][]float32)
for _, file := range files {
f, _ := os.Open("data/" + file.Name())
scanner := bufio.NewScanner(f)
for scanner.Scan() { // reading line by line
if rec := parseData(scanner.Text()); rec.coords != "" {
aggregated[rec.coords] = append(aggregated[rec.coords], rec.avg)
}
}
f.Close()
}
outputFile, _ := os.Create("output.csv")
w := csv.NewWriter(outputFile)
defer w.Flush()
defer outputFile.Close()
if *memprofile != "" {
memf, _ := os.Create(*memprofile)
pprof.WriteHeapProfile(memf)
memf.Close()
}
for coordinates, yearlyTemps := range aggregated {
row := []string{coordinates, fmt.Sprintf("%.2f", average(yearlyTemps))}
w.Write(row)
}
}
func parseData(line string) record {
seg := strings.Fields(line) // 没有 strings.Fields 的替代函数
if len(seg) != 14 {
return record{}
}
var temp float32 // 明确知道有 12 个月,不需要通过 slice 来保存计算 avg
for i := 2; i < 14; i++ {
t, _ := refloat.ParseFloat(seg[i], 32) // 使用 refloat 替换 strconv.ParseFloat
temp += float32(t)
}
return record{coords: seg[1] + ":" + seg[0], avg: temp / 12} // 更简单的记录结构
}
func average(input []float32) float32 {
var sum float32
for _, v := range input {
sum += v
}
return sum / float32(len(input))
}
如果我们运行这个优化版本,我们应该会看到CPU和内存使用方面显著的改进。
go build -o bin main.go
./bin -memprofile mem.prof
go tool pprof bin mem.prof
File: bin
Type: inuse_space
Time: Apr 7, 2024 at 8:55pm (IDT)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top5
Showing nodes accounting for 57.10MB, 100% of 57.10MB total
flat flat% sum% cum cum%
55.60MB 97.37% 97.37% 57.10MB 100% main.main
0.50MB 0.88% 98.25% 0.50MB 0.88% strings.Fields
0.50MB 0.88% 99.12% 0.50MB 0.88% bufio.(*Scanner).Text (inline)
0.50MB 0.88% 100% 1MB 1.75% main.parseData
0 0% 100% 57.10MB 100% runtime.main
太棒了!我们已将内存消耗从1.7GB减少到57.1MB。
让我们也检查一下CPU profile:
(pprof) top1 -cum
Showing nodes accounting for 140ms, 2.05% of 6830ms total
Dropped 103 nodes (cum <= 34.15ms)
Showing top 1 nodes out of 67
flat flat% sum% cum cum%
140ms 2.05% 2.05% 5970ms 87.41% main.main
看起来很好,CPU消耗现在从14秒下降到大约7秒!
Profiling 运行中的服务器
到目前为止,我们一直在分析一个单独的短时程序。但如果我们想分析一个服务器应用程序怎么办?选择分析点和触发分析过程会稍微复杂一些。而且,我们可能会在无法访问分析过程生成文件的环境中运行应用程序。
使用 net/http/pprof
内置的net/http/pprof包为分析Go应用程序提供了一个HTTP接口。它使用了我们之前一直在使用的相同的pprof工具,但不是将结果写入文件,而是通过HTTP提供它们,并自动将处理程序注册到HTTP服务器。你只需导入这个包并启动一个服务器。
import _ "net/http/pprof"
func main() {
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
// your application code ...
}
要分析堆和CPU使用情况,我们可以使用以下端点:
在分析方面,这些端点等同于我们之前使用的WriteHeapProfile和StartCPUProfile函数。当然,我们不能像以前那样精确地协调分析过程,而是试图捕捉服务器负载重的时刻。
值得一提的是,还有其他类型的分析更适合分布式、类似服务器的应用程序。通过使用net/http/pprof包,我们可以轻松访问:
- http://localhost:6060/debug/pprof/block - goroutine阻塞分析,显示goroutine在哪里阻塞。(你需要启用runtime.SetBlockProfileRate)
- http://localhost:6060/debug/pprof/mutex - 报告锁定情况(你需要启用runtime.SetMutexProfileFraction)
- http://localhost:6060/debug/pprof/trace?secods=10 - 提供可通过 go tool tracer 访问的最小跟踪分析
总结
软件工程中最难的任务之一是检测不明显的隐藏问题。虽然你会在可能发生错误的地方找到错误日志,或者查看内存泄漏过程的直方图,但一个好的分析将通过显示代码中的确切行来展示你的程序出现问题的地方。