JavaScript解析HTML
在本文中,我们将探索解析HTML内容的基础知识,以及在JavaScript中解析HTML的各种方法和库。我们还将介绍最佳实践和常见问题,以及实际应用。
随着数据需求的增加,提取、处理和理解数据的需求也在增加。但大多数数据都存在于网站中。那么,如何以编程方式访问这些数据呢? 解决方案在于自动化分析、提取和转换原始数据为结构化、易读格式的过程。这一过程被称为HTML解析,我们将向你展示如何使用JavaScript来实现这一点。 那么让我们开始吧!
Contents
在JavaScript中解析HTML文件
解析HTML涉及分析HTML字符串集合,包括HTML标签、属性及其值,以生成结构化表示,即文档对象模型(DOM)。这个想法是映射整个页面,以便我们可以轻松提取特定数据或定位要交互的元素,如按钮和表单。
HTML被设计为可编程解析。该过程包括将HTML文档分解为其关键组成元素,直到最小组件,并构建DOM。
例如,让我们考虑以下HTML示例:
<head>
<title>
</title>
</head>
<body>
<h1>Parsing HTML</h1>
<div>
<p>Using JavaScript</p>
<a ID="URL" href="example.com">
URL
</a>
</div>
</body>
不深入探讨技术实现,HTML文档在解析过程中会经历几个步骤,包括标记化(tokenization)。 这一过程使得可以遍历HTML树的每个节点,理解其结构,操作DOM,并以编程方式从HTML文档中提取相关数据。
JavaScript HTML解析器
有几种可用的库和API可以用来在JavaScript中解析HTML,每种都有独特的功能和用例。我们将介绍以下内容:
- DOMParser API
- Cheerio
- Axios
- Parse5
- JSDOM
1. 使用DOMParser API
DOMParser API是浏览器环境中的内置接口,允许你从字符串中解析HTML源代码为DOM文档。这对于以编程方式操作和提取HTML内容非常有用。
简而言之,DOMParser API提供了DOMParser构造函数,你可以用它创建一个新的DOM解析器对象。从这个对象,你可以调用 parseFromString 方法轻松将HTML内容解析为DOM文档。
让我们来看一个例子:
const htmlString = `
<div>
<h1>Hello, World!</h1>
<p>This is a paragraph.</p>
</div>
`;
const parser = new DOMParser();
const d = parser.parseFromString(htmlString, 'text/html');
console.log(d);
在这个例子中,我们首先定义了一个包含一些HTML元素的字符串 htmlString —— 一个div元素、标题和段落标签及其各自的值。
要解析这个内容,我们需要先创建一个新的 DOMParser 对象实例。然后,使用 parseFromString 方法将 htmlString 解析为DOM Document 对象。
在这种情况下,输出是完整的DOM树结构,包括应该存在的其他HTML文档元素,例如和元素。
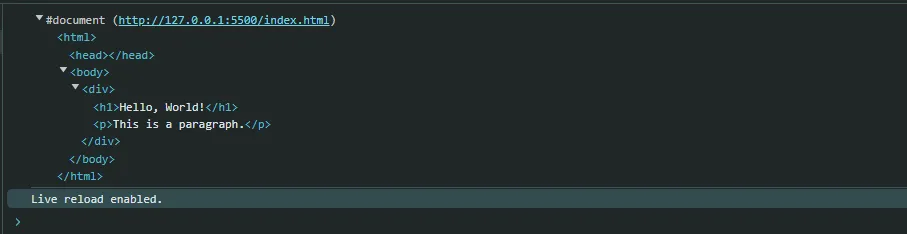
请注意,parseFromString 方法接受两个参数:你想解析的HTML字符串,以及一个内容类型参数,在本例中是 'text/html'。指定你想解析的内容类型很重要,因为该方法也可以解析XML内容。
要提取相关数据,你可以使用 querySelector 方法在解析后的文档中查找元素并提取其文本内容。
const heading = document.querySelector('h1').textContent;
console.log(heading); // 输出:Hello, World!
根据你的具体用例,你可能还想将DOM树转换回HTML字符串。这个过程称为序列化。
为此,你需要使用不同的接口,即 XMLSerializer。
这是一个例子:
const serializer = new XMLSerializer();
const serializedHTML = serializer.serializeToString(document);
console.log(serializedHTML); // 字符串形式打印当前页面 HTML
就像 DOMParser 构造函数一样,你需要先创建一个XMLSerializer的新实例。然后,我们调用 serializeToString 方法,传入DOM文档,将其转换回HTML字符串。
序列化DOM树在需要以编程方式操作HTML结构并将其转换回字符串以进行进一步处理或渲染的场景中非常有用。
2. 使用 Cheerio
Cheerio 是jQuery core的快速、灵活和精简实现,提供了一个相当可用的API,用于以熟悉的jQuery风格解析和操作HTML。
通常,Node.js不允许解析和操作标记,因为它在浏览器外部执行代码。然而,通过使用Cheerio库,你可以在Node.js环境中解析和遍历HTML文档。
在使用Cheerio之前,请确保你对Node.js及其相关技术有足够的了解;你将从这里开始在服务器端工作。
在你的首选项目目录中使用以下命令初始化一个Node.js项目。
npm init --y
此命令将在项目目录的根目录中创建一个 package.json 文件,以管理依赖项、脚本和配置。
接下来,安装 Cheerio。你可以使用首选的包管理器安装该包,或者使用 npm:
npm install cheerio
使用Cheerio的第一步是加载要解析的HTML内容。这是确保Node.js在服务器环境中直接访问标记内容所需的。
要加载HTML内容,我们将使用 cheerio.load() 方法,传递文档类型参数——要加载的HTML文档。
要使用Cheerio解析,创建一个 app.js 文件,并粘贴此代码:
import cheerio from 'cheerio';
const htmlString = `
<div>
<h1>Hello, World!</h1>
<p>This is a paragraph.</p>
</div>
`;
const $ = cheerio.load(htmlString);
在这个例子中,我们首先将HTML字符串加载到Cheerio中。然后,我们可以使用类jQuery语法查询和操作DOM,包括如下访问目标内容:
const heading = $('h1').text();
console.log(heading); // 输出:Hello, World!
💡 请确保在package.json文件中包含
"type": "module"以启用Node.js应用中的ES6模块。
要验证这一点,启动node服务器并观察终端中的输出。
node app.js
3. 使用 Axios
在上面的例子中,我们解析并提取了一个基本HTML文档结构中的数据。但是当你想要解析像有几个网页的网站这样的大型HTML文档时会怎样呢?
在这种情况下,原理是相同的;但是,你需要先使用诸如 Axios 或 Fetch API 之类的工具下载网站的原始HTML。对于本教程,我们将使用Axios。
首先,在终端上运行以下命令安装它:
npm install axios
现在,让我们看一个例子:
import axios from 'axios';
import cheerio from 'cheerio';
async function fetchAndParse(url) {
try {
const response = await axios.get(url);
if (response.status !== 200) {
throw new Error(`Failed to fetch webpage: ${url}`);
}
const html = response.data;
const $ = cheerio.load(html);
const title = $('title').text();
console.log(`Page Title: ${title}`);
} catch (error) {
console.error('Error fetching or parsing webpage:', error);
}
}
fetchAndParse('<https://jsonplaceholder.typicode.com>');
一旦下载了网页,使用Cheerio加载它,然后解析它。加载内容后,从解析对象遍历HTML文档非常容易,可以提取尽可能多的数据以进一步处理或在你的应用程序中使用。
虽然非常基础,但上面的代码片段是一个很好的网络抓取示例。
4. 使用 Parse5
Parse5 是一个灵活的 HTML 解析器,它提供了一个简单的 API,用于解析和序列化 HTML 文档。它设计为其他工具的构建块,但也可以直接用于简单任务的 HTML 解析。
要使用 Parse5,请在本地环境中安装它:
npm install --save parse5
现在,让我们来看一个示例。你可以将这段代码粘贴到你的 app.js 文件中。
const parse5 = require ('parse5') ;
const htmlString = `
<div>
<h1>Hello, World!</h1>
<p>This is a paragraph.</p>
</div>
`;
const document = parse5.parse(htmlString);
// 遍历文档以查找元素
function traverse(node) {
if (node.nodeName === 'h1') {
console.log(node.childNodes[0].value); // 输出:Hello, World!
}
if (node.childNodes) {
node.childNodes.forEach(traverse);
}
}
traverse(document);
在这个示例中,与其他解析技术类似,我们需要加载并解析 HTML 字符串到一个文档中。然后,我们遍历文档树以查找和操作元素。
然而,当你想遍历 DOM 对象以提取值时,对于大型网页来说,使用 Parse5 进行遍历和检索内容并不那么直观。
💡 请注意,Parse5 不提供默认导出,这与 ES6 模块默认情况不同。因此,使用标准的 ES6
import语法导入包可能会导致问题,故建议使用传统的require语法来导入和使用包。
5. 使用 JSDOM
JSDOM 是另一个很棒的库,它为 Node.js 模拟了一个类似浏览器的环境,让你可以像在真实浏览器中一样解析和操作 HTML。
使用 JSDOM 相对简单。它期望你将有效的 HTML 内容作为字符串传递给其构造函数。然后,它会像浏览器一样解析这些 HTML。从那里,你可以操作、提取或与 HTML 元素交互。
要使用 JSDOM,请使用以下命令安装它:
npm install jsdom
这里是使用 JSDOM 的一个基本示例:
import { JSDOM } from 'jsdom';
const htmlString = `
<div>
<h1>Hello, World!</h1>
<p>This is a paragraph.</p>
</div>
`;
const dom = new JSDOM(htmlString);
const document = dom.window.document;
const heading = document.querySelector('h1').textContent;
console.log(heading); // 输出:Hello, World!
在这个示例中,需要注意的是,从构造函数返回的对象包含解析 HTML 文档的数据以及 JSDOM 用于解析该文档的元数据。要访问实际的文档,你需要读取 window 属性,这类似于浏览器中的 window 属性。
之后,你读取 document 属性,这会让你进入实际的 DOM,就像在普通浏览器中的 JavaScript 中工作一样。从那里,你可以使用 DOM 方法选择和操作元素。
附加:使用正则表达式解析 HTML
使用正则表达式解析 HTML 通常不推荐,因为处理复杂 HTML 结构时会非常复杂且容易出错。然而,对于简单的 HTML 解析任务,正则表达式有时是一个可行的选择。
一个实现使用正则表达式解析的好例子是实现客户端表单的数据验证,例如检查用户是否提供了正确的格式或密码。
这里是使用正则表达式解析 HTML 内容的简单示例。然而,重要的是要注意,在这个示例中,我们实际上是在使用 JavaScript 的本地 match() 方法解析一个字符串,而不是执行全面的 HTML 解析。该方法返回与提供的正则表达式匹配的结果;否则返回 null。
const htmlString = `
<div>
<h1>Hello, World!</h1>
<p>This is a paragraph.</p>
</div>
`;
const headingMatch = htmlString.match(/<h1>(.*?)<\/h1>/);
if (headingMatch) {
console.log(headingMatch[1]); // 输出:Hello, World!
}
在这个示例中,我们使用正则表达式模式 /<h1>(.*?)<\\/h1>/ 来匹配 <h1> 标签并提取其内容。
让我们来拆解这个模式:
/<h1>: 这一部分匹配开头的<h1>标签。(.*?): 括号创建一个捕获组以访问<h1>标签内的内容。.*?是一个非贪婪修饰符,它尽可能少地匹配任何字符序列(不包括换行符)。<\\/h1>: 这一部分匹配结束的</h1>标签。非贪婪量词。.*?在这里至关重要。没有?,贪婪修饰符.*. 会尽可能多地匹配内容,可能包括<h1>标签外的内容。
虽然正则表达式可以很好地处理基本的 HTML 解析任务,但通常推荐使用像 Cheerio 或 JSDOM 这样的专用 HTML 解析库。
这些库提供了一种更健壮和高效的方式来解析和操作 HTML 文档,同时提供了广泛的方法和功能来处理 DOM。
如果你决定使用正则表达式进行简单的 HTML 解析任务,请确保在各种场景和边缘情况下彻底测试你的模式,以确保它们按预期工作,并且不会在你的应用程序中引入漏洞或错误。
解析 HTML 时的常见问题
在解析过程中可能会遇到几个问题,包括:
1. HTML 内容格式不正确
这是你可能遇到的最基本的问题。浏览器和解析器处理格式不正确的 HTML 的方式可能不同,导致结果不一致。
格式不正确的 HTML 可能包括缺失或不匹配的标签、不正确的属性名称或值、或额外或缺失的字符。
为了解决这个问题,请确保仔细检查你的 HTML 代码的语法,并确保它是格式正确的和有效的。
然而,你不需要过于担心,因为大多数代码编辑器具有语法高亮和错误检测功能,可以帮助你识别和修复这些类型的问题。
2. 错误的网页脚本
在你的网页上运行的 JavaScript 代码如果有错误、冲突或兼容性问题,可能会影响 HTML 解析和 DOM 操作,导致意外或不希望的行为。
确保彻底测试你的 JavaScript 代码,并确保它没有错误和冲突。
你还可以使用像 linter 和单元测试这样的工具来捕捉和修复任何问题,以防止它们影响 HTML 解析过程。
3. 性能瓶颈
解析大型 HTML 文档可能会很慢且占用大量内存,如果未进行适当优化,会导致性能问题。
有几种技术可以提高你的应用程序的性能,包括渐进渲染、延迟加载以及优化 HTML 结构以减少文档的整体复杂性和大小。
此外,你可以对你的代码进行分析,识别可能导致性能问题的区域。
4. 安全漏洞
在处理 HTML 时,总是存在安全漏洞的风险,特别是跨站脚本攻击(XSS)。
XSS 攻击发生在恶意代码通过未经清理的用户输入注入到网页中时。
为避免这种情况,绝对关键的是,你始终要在应用程序中使用用户生成的 HTML 输入之前,对其进行清理和验证。
HTML 解析的用例
HTML 解析有多种用例,主要在 Web 开发、数据处理和分析中。
1. 网页抓取和数据提取
虽然一些网络数据通过专用 API 可用,但有相当一部分数据只能通过网站的 HTML 内容访问。要访问这些数据,你需要设置自动化的数据收集过程,并使用解析器来读取和处理它。
通常,这完全就是网页抓取——使用抓取器(自动脚本)从网站中提取数据。这个过程涉及向网站发送 HTTP 请求,检索 HTML 内容,然后解析 HTML 以定位和提取所需的数据。
让我们来看一个使用流行的 Hacker News 网站作为案例研究的网页抓取示例。
我们可以使用 HTML 解析从网站中提取相关数据,例如头条新闻的标题、URL 和分数。
创建一个新的 scraper.js 文件,并粘贴这段代码:
import axios from 'axios';
import cheerio from 'cheerio';
async function scrapeHackerNews() {
try {
const response = await axios.get("https://news.ycombinator.com/");
const $ = cheerio.load(response.data);
const stories = [];
const rows = $('tr');
let currentArticle = null;
let currentRowType = null;
rows.each((index, row) => {
const $row = $(row);
if ($row.attr('class') === 'athing') {
currentArticle = $row;
currentRowType = 'article';
} else if (currentRowType === 'article') {
if (currentArticle) {
const titleElem = currentArticle.find('.title');
if (titleElem.length) {
const articleTitle = titleElem.text().trim();
const articleUrl = titleElem.find('a').attr('href');
const subtext = $row.find('.subtext');
const points = subtext.find('.score').text();
stories.push({
title: articleTitle,
url: articleUrl,
points: points,
});
}
}
currentArticle = null;
currentRowType = null;
} else if ($row.attr('style') === 'height:5px') {
return;
}
});
return stories;
} catch (error) {
console.error('An error occurred:', error);
return [];
}
}
在这个示例中,在 scrapeHackerNews() 函数内部,我们首先使用 Axios 向 Hacker News 首页发送 GET 请求,然后使用 Cheerio 将 HTML 内容加载到一个类似 jQuery 的对象 $ 中。
然后,函数将遍历页面上的 tr 元素,这些元素代表 Hacker News 上的各个故事。它识别包含故事信息的行(具有 'athing' 类的那些)并提取每个故事的标题、URL 和分数。这些故事详情随后存储在一个名为 stories 的数组中。
最后,调用以下函数将 stories 数组中每个故事的标题、URL 和分数记录到控制台:
scrapeHackerNews().then((stories) => {
stories.forEach((story) => {
console.log('Title:', story.title);
console.log('URL:', story.url);
console.log('Points:', story.points);
console.log('-'.repeat(10));
});
需要注意的是,网页抓取可能是一项具有挑战性的任务,因为网站经常更改其 HTML 结构和布局,这使得需要定期更新抓取逻辑。此外,一些网站可能会采取措施来检测和防止抓取,例如速率限制或 IP 封锁。
你应该了解这些障碍,并实施适当的策略,例如使用轮换代理(rotating proxy),以确保抓取器的可靠性和可持续性。
2. 可访问性审计
可访问性审计是分析网页以识别可能阻止残障用户有效访问或交互内容的潜在可访问性问题的过程。
这个过程涉及解析网页的 HTML 结构,以程序化地检查各种可访问性标准。
你可以评估各种可访问性因素。然而,这些因素在很大程度上取决于你的最终用户和你的具体可访问性策略。但通常,你可以分析你的网站 HTML 以检查:
- 语义 HTML 标签的正确使用:确保页面使用适当的 HTML 标签(例如,
<h1>、<h2>、<h3>等)来定义文档结构和层次。这有助于屏幕阅读器和其他辅助技术理解内容的组织。 - 图像的替代文本:验证页面上的所有图像是否有意义的替代文本(alt 属性),描述图像的目的和内容。
- 键盘可访问性:检查页面上的所有交互元素(例如,链接、按钮、表单控件)是否可以仅使用键盘访问和操作,而无需鼠标。
让我们来看一个使用 Cheerio 库执行 HTML 文件的可访问性审计的示例。创建一个 audit.js 文件,并粘贴这段代码:
import cheerio from 'cheerio';
import fs from 'fs';
async function auditAccessibility(htmlFilePath) {
try {
const html = await fs.promises.readFile(htmlFilePath, 'utf8');
const $ = cheerio.load(html);
// 检查语义 HTML 标签
const headings = $('h1, h2, h3, h4, h5, h6');
if (headings.length === 0) {
console.log('No headings found on the page. Consider adding meaningful headings.');
} else {
let prevHeadingLevel = 0;
headings.each((index, heading) => {
const headingLevel = parseInt(heading.tagName[1]);
if (headingLevel > prevHeadingLevel + 1) {
console.log(`Heading level jump from ${prevHeadingLevel} to ${headingLevel} on the page. Consider using proper heading hierarchy.`);
}
prevHeadingLevel = headingLevel;
});
}
// 检查图像替代文本
const images = $('img');
images.each((index, img) => {
const altText = $(img).attr('alt');
if (!altText || altText.trim() === '') {
console.log(`Image at index ${index} does not have alternative text. Consider adding a meaningful alt attribute.`);
}
});
// 检查键盘可访问性
const focusableElements = $('a, button, input, textarea, select, [tabindex]');
focusableElements.each((index, element) => {
const tabIndex = $(element).attr('tabindex');
if (tabIndex && parseInt(tabIndex) < 0) {
console.log(`Element at index ${index} has a negative tabindex value, which makes it inaccessible via keyboard.`);
}
});
console.log('Accessibility audit complete.');
} catch (error) {
console.error('Error during accessibility audit:', error);
}
}
auditAccessibility('index.html');
在这个例子中,auditAccessibility() 函数在调用时执行可访问性审计。它将一个 HTML 文件的文件路径作为输入,并使用 fs.promises.readFile() 读取文件的内容,存储在 html 变量中。
接下来,我们使用 cheerio.load() 函数解析 HTML 内容并创建一个类似 jQuery 的 $ 对象,该对象可用于遍历和操作 HTML 结构。
基本上,该函数执行以下可访问性检查:
- 检查标题元素:首先使用
$()函数检查页面上的所有标题元素。如果未找到任何标题元素,则记录一条警告消息。 - 检查 alt 文本:查找页面上的所有
img元素,并检查每个元素是否具有有意义的alt属性。如果某个图片缺少替代文本,则记录一条警告消息。 - 检查键盘可访问性:查找页面上的所有交互元素(链接、按钮、表单控件等)是否可以接收键盘焦点。检查这些元素中是否有任何具有负的
tabindex值,这会使键盘用户无法访问它们,如果发现任何此类元素,则记录一条警告消息。
要测试这一点,创建一个 index.html 文件,并复制粘贴以下内容:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Test Page</title>
</head>
<body>
<h1>Accessibility Audit Test Page</h1>
<section>
<h2>Section 1</h2>
<p>Hello.</p>
<img src="image1.jpg" alt="Image 1">
<a href="#" tabindex="-1">Inaccessible Link</a>
</section>
<section>
<h3>Subsection 1</h3>
<p>World!.</p>
<img src="image2.jpg">
</section>
<section>
<h4>Subsection 2</h4>
<p> Hello.</p>
<button tabindex="-1">Inaccessible Button</button>
</section>
<footer>
<p> @2024</p>
</footer>
</body>
</html>
此 index.html 文件包括了 auditAccessibility() 函数会检测到的问题示例,例如缺少标题、没有替代文本的图片和具有负 tabindex 值的交互元素。因此,当你运行 Node.js 服务器时,应该会在终端上看到如下响应:
Image at index 1 does not have alternatie text. Consider adding a meaningful alt attribute.
Element at index 0 has a negative tabindex value, which makes it inaccessible via keyboard.
...
Accessibility audit complete.
总结:在 JavaScript 中解析 HTML 的最佳实践
为了确保在 JavaScript 中解析 HTML 时获得正确的结果,你可以实施几个最佳实践。以下是一些最重要的实践:
- 使用合适的工具
选择适合你具体需求的解析器。对于简单任务,DOMParser 可能就足够了,而像 JSDOM 或 Cheerio 这样的库更适合用于更复杂的操作。
- 验证和清理输入
始终验证和清理输入的 HTML,以避免安全风险,例如 XSS 攻击。这一点尤其重要,如果解析过程是应用程序中依赖于解析过程的较大工作流程的一部分。
- 优化性能
解析大量 HTML 可能会很慢且占用大量内存,因此你可能需要优化代码以提高性能。例如,在使用 Cheerio 时,你可以使用 .find() 方法和特定选择器来仅定位你需要的元素,而不是遍历整个文档结构。
- 避免使用正则表达式进行复杂解析
虽然正则表达式对于简单的解析任务可能很有用,但你应该避免将其用于复杂的 HTML 解析任务。
下一步
现在是时候释放你的创造力,尝试一些想法,并构建一些很棒的项目了!
这只是冰山一角。除了我们涵盖的技术之外,还有其他很棒的选项可以探索,比如 HTMLParser2、node-html-parser 等。